더보기
너무 행복한 추석이었다🙌
복습을 하겠다고 다짐했던 난, 명절 음식과 함께 잡아 먹히고 말았다.
푹 쉬고 왔지만 앞으로가 막막하다 (팀과제😶😶😶)
목,금 이틀 동안은 그동안 배웠던 개념을 다시 리마인드 / 실습 예제를 풀면서 마무리 했다!
진짜 내 머리는 닭이라도 되는 것 마냥 다 까먹었지만.. 중요 개념들만 다시 적어보자 흑흑
* 데이터처리 라이브러리
- Pandas
* 데이터시각화 라이브러리
- Matplotlib / Seaborn
Pandas
- .columns : 컬럼명 확인
- .head() : 데이터의 상단 5개 행 출력
- .tail() : 데이터의 하단 5개 행 출력
- .shape : (행, 열) 크기 확인
- .info() : 데이터에 대한 전반적인 정보 제공
- .type() : 데이터 타입 확인
- .isna( ) : 결측 값은 True 반환, 그 외에는 False 반환
- .notna( ) : 결측 값은 False 반환, 그 외에는 True 반환
- .dropna(axis=1) : 결측 값이 들어있는 열 전체 삭제
- .notna( ) : 결측 값은 False 반환, 그 외에는 True 반환
- .dropna( ) == .dropna(axis=0) : 결측 값이 들어있는 행 전체 삭제.
- .loc[] : 행 이름과 열 이름을 사용
- .iloc[] : 행 번호와 열 번호를 사용
- .mean() : 평균값
- .median() : 중앙값
- .describe() : 다양한 통계량 요약
- .agg() : 여러개의 열에 다양한 함수를 적용
- 모든열에 여러 함수를 매핑 : group객체.agg([함수1, 함수2, 함수3, …])
- 각 열마다 다른 함수를 매핑 : group객체.agg({‘열1’: 함수1, ‘열2’: 함수2, …})
print(titanic.agg({'Age':['min','max','median','std'],
'Fare' :['min','max','mean','median']}))
- .groupby() : 그룹별 집계
ex ) 각 와인 타입별 pH의 평균을 구하시오.
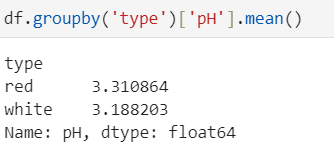
- .value_counts() : 값의 개수
- 행 추가 : df.loc[‘새로운 행 이름‘] = 데이터 값
- 열 추가 : df[‘추가하려는 열 이름‘] = 데이터 값
- 행 삭제 : df.drop(index, axis = 0)
- 행 중복 제거 : df.drop_duplicates()
- 열 삭제 : df.drop(변수명, axis = 1)
- 인덱스 1부터 달기 : df.index = [i+1 for i in range(len(df))] <- 다른방법도 있음(까먹음)
Matplotlib
모듈의 함수를 이용하여 간편하게 그래프 만들고 변화를 줄 수 있음
- 한 개의 숫자 리스트 형태로 값을 입력하면 y값으로 인식
- x값은 기본적으로 [0, 1, 2, 3]으로 설정됨
- plt.show( ) 함수는 그래프를 화면에 나타나도록 함
plt.plot([2,3,4,5])
plt.show()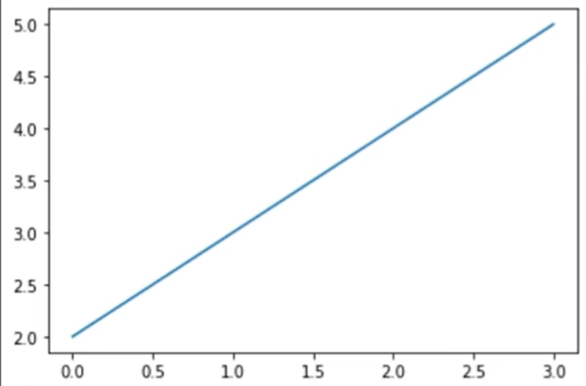
- 두 개의 숫자 리스트 형태로 값을 입력하면 순서대로 x, y 값으로 인식
- 순서쌍(x, y)으로 매칭된 값을 좌표평면 위에 그래프 시각화
plt.plot([1,2,3,4],[1,4,9,10])
plt.show()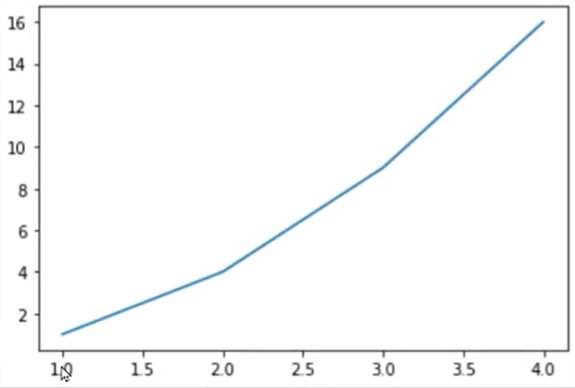
- xlabel() 함수를 사용하여 그래프의 x축에 대한 레이블 표시
- ylabel() 함수를 사용하여 그래프의 y축에 대한 레이블 표시
- 범례(Legend)는 그래프에 데이터의 종류를 표시하기 위한 텍스트
- legend() 함수를 사용해서 그래프에 범례 표시
- plot() 함수에 label 파라미터 값으로 삽입
- plt.title() : 제목
- xlim() : X축이 표시되는 범위 지정 [xmin, xmax]
- ylim() : Y축이 표시되는 범위 지정 [ymin, ymax]
- axis() : X, Y축이 표시되는 범위 지정 [xmin, xmax, ymin, ymax]
- 입력 값이 없으면 데이터에 맞게 자동으로 범위 지정
plt.plot([1, 2, 3, 4], [1, 4, 9, 16],label='Square')
plt.xlabel('X-Label')
plt.ylabel('Y-Label')
plt.legend()
plt.show()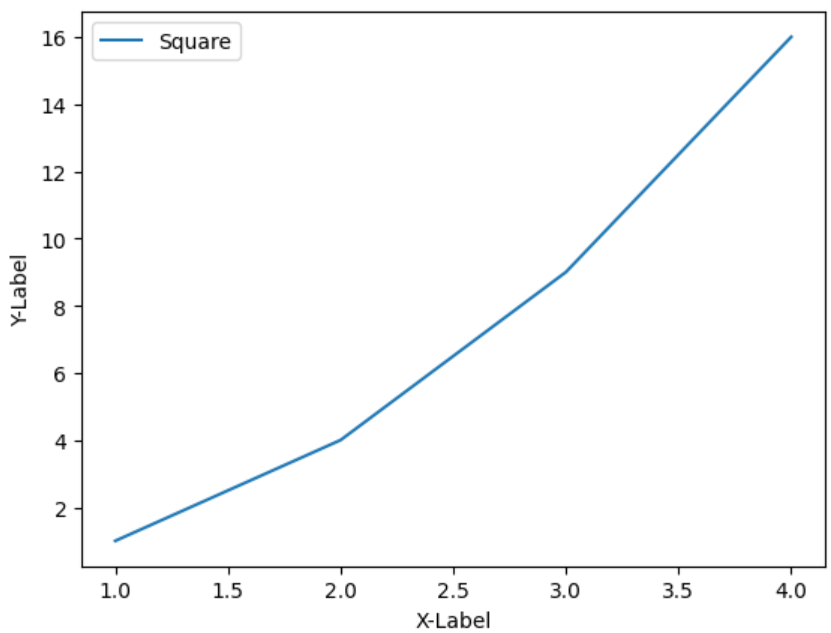
Matplotlib 선 종류
- plot() 함수의 포맷 문자열 사용
- '-' (Solid), '- -' (Dashed), ' : ' (Dotted), ' -. ' (Dash-dot)
plt.plot([1, 2, 3], [4, 4, 4], '-', color='C0', label='(0, (1, 1))')
plt.plot([1, 2, 3], [3, 3, 3], '--', color='C0', label='(0, (1, 5))')
plt.plot([1, 2, 3], [2, 2, 2], '-.', color='C0', label='(0, (5, 1))')
plt.plot([1, 2, 3], [1, 1, 1], ':', color='C0', label='(0, (3, 5, 1, 5))')
plt.xlabel('X-Label')
plt.ylabel('Y-Label')
plt.axis([0.8, 3.2, 0.5, 5.0])
plt.legend(loc='upper right', ncol=2)
plt.tight_layout()
plt.show()
★plt.tight_layout() <- 여백없이 그래프 나오게하기
Matplotlib 마커
- 기본적으로는 실선 마커
- plot() 함수의 포맷 문자열 (Format string)을 사용해서 마커 지정
- 'ro’는 빨간색 (‘red’)의 원형 (‘circle’) 마커를 의미
- 'k^’는 검정색 (‘black’)의 삼각형 (‘triangle’) 마커를 의미
- plot() 함수의 marker 파라미터 값으로 삽입
# 'b' blue, 'ro' red+circle
# 's' square, 'D' diamond
# '$문자$' 문자 마커
plt.plot([4, 5, 6],'b' )
plt.plot([3, 4, 5],'ro')
plt.plot([2, 3, 4], marker = 'x')
plt.plot([1, 2, 3], marker = 's')
plt.plot([0, 1, 2], marker = '$A$')
plt.show()
예시)
import matplotlib.pyplot as plt
plt.plot([1, 2, 3, 4], [2, 3, 5, 10], color='#e35f62',
marker='o', linestyle='--')
plt.xlabel('X-Axis')
plt.ylabel('Y-Axis')
plt.show()
Matplotlib 눈금표시
- xticks(), yticks() 함수는 각각 X축, Y축에 눈금 설정
- xticks(), yticks() 함수의 label 파라미터 값으로 눈금 레이블 설정
Matplotlib 그래프 종류
- matplotlib.pyplot.bar( ) : 막대 그래프
- matplotlib.pyplot.barh( ) : 수평 막대 그래프
- matplotlib.pyplot.scatter( ) : 산점도
- matplotlib.pyplot.hist( ) : 히스토그램
- matplotlib.pyplot.errorbar( ) : 에러바
- matplotlib.pyplot.pie( ) : 파이 차트
- matplotlib.pyplot.matshow( ) : 히트맵
* Matplotlib 막대그래프 (bar)
x=[1,2,3]
year=['2021','2022','2023']
values=[500,200,400]
plt.bar(x,values,color = ['r','k','b'],width=0.8)
plt.xticks(x,year)
plt.show()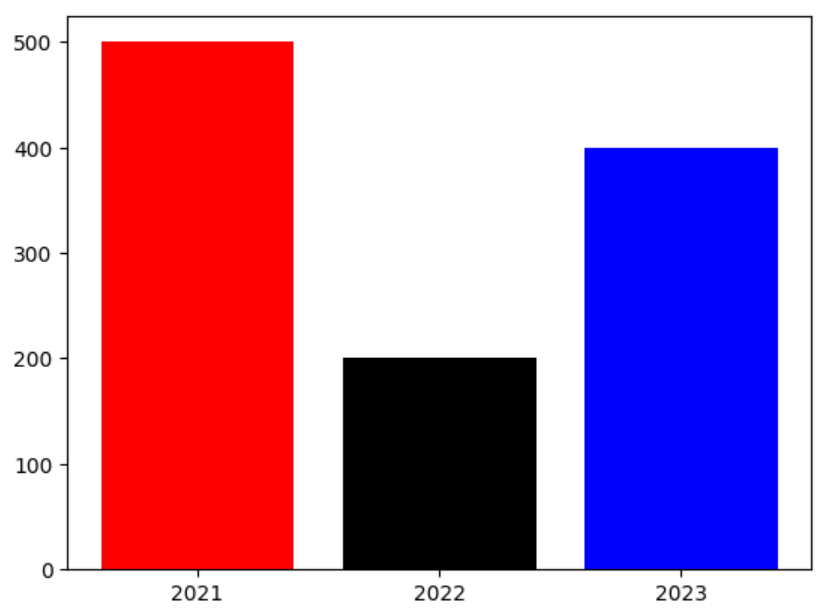
* Matplotlib 산점도 (scatter)
- scatter() 함수의 color 파라미터 값으로 마커의 색상 설정
- scatter() 함수의 size 파라미터 값으로 마커의 크기 설정
import numpy as np
np.random.seed(0)
#★괄호 안에 0을 입력하면 한 번 만들어진 랜덤 함수를 바꾸지 않고 계속 쓸 수 있음
n = 50
x = np.random.rand(n)
y = np.random.rand(n)
size = (np.random.rand(n)*10)**2
colors = np.random.rand(n)
plt.scatter(x,y,s=size,c=colors)
plt.show()
* Matplotlib subplot : 여러 개 그래프 시각화
- plt.subplot(row, column, index)
- tight_layout() 함수는 모서리와 서브플롯의 모서리 사이의 여백(padding)을 설정

# linspace : 몇등분할지 생각하면 디폴트는 50
# np.linspace(0, 10) : 0부터 10까지 50등분한 결과를 배열로 반환
# y값은 역동적인 그래프를 위한 np.cosine 함수 이용
# np.pi 함수로 원주율(파이) 값 사용
x1 = np.linspace(0,10)
x2 = np.linspace(0,10)
y1 = np.cos(2*np.pi*x1)
y2 = np.cos(2*np.pi*x2)
# subplot
# nrows=2, ncols=1, index=1
plt.subplot(2,1,1)
plt.plot(x1,y1,'o-')
plt.title('1st graph')
plt.subplot(2,1,2)
plt.plot(x2,y2,':')
plt.title('2nd graph')
plt.tight_layout()
plt.show()

* Matplotlib subplots : 한 좌표 평면 위에 여러 개 그래프 시각화
- plt.subplots() 함수의 디폴트 파라미터는 1이며 즉 plt.subplots(nrows=1, ncols=1) 의미
- plt.subplots() 함수는 figure와 axes 값을 반환
- figure : 서브플롯 안에 몇 개의 그래프가 있던지 상관없이 그걸 담는 전체 사이즈를 의미
- axe : 전체 중 낱낱개 의미 / ex) 서브플롯 안에 2개(a1,a2)의 그래프가 있다면 a1, a2 를 일컬음
- .twinx() 함수는 ax1과 축을 공유하는 새로운 Axes 객체 생성
# x는 X축에 표시될 연도이고, y1, y2는 y 값
x = ['2021','2022','2023']
y1 = np.array([1,5,15])
y2 = np.array([2,4,8])
# plt.subplots() 함수는 여러 개 그래프를 한 번에 가능, 객체 생성
# plt.subplots(nrows=1, ncols=1) = plt.subplots()
fig, ax1 = plt.subplots()
# -s(solid line style + square marker), alpha(투명도)
ax1.plot(x,y1,'-s',color='blue',markersize=8,linewidth=6,alpha=0.9)
# .twinx() 함수는 ax1과 축을 공유하는 새로운 Axes 객체 생성
ax2 = ax1.twinx()
ax2.bar(x,y2,color='orange',alpha=0.6,width=0.7)
#plt.twinx()
#plt.bar(x, y2, color='deeppink', alpha=0.5)
plt.show()

'패스트캠퍼스🥕' 카테고리의 다른 글
| ■패스트캠퍼스 데이터 분석 부트캠프■ 9주차 #SQL 중급 문법/코딩테스트 연습 (0) | 2024.10.18 |
|---|---|
| ■패스트캠퍼스 데이터 분석 부트캠프■ 8주차 #SQL 기초문법 (0) | 2024.10.11 |
| ■패스트캠퍼스 데이터 분석 부트캠프■ 4주차 #python 크롤링/전처리/시각화 (3) | 2024.09.13 |
| ■패스트캠퍼스 데이터 분석 부트캠프■ 3주차 #데이터 분석을 위한 python (2) | 2024.09.06 |
| ■패스트캠퍼스 데이터 분석 부트캠프■ 2주차 #데이터 분석을 위한 기초 수학/통계 (0) | 2024.08.30 |