부트캠프 4주차를 마치며...
오랜만이다 이런 기분. 마치 내가 바보가 된 것 같은...ㅋㅋㅋ
코딩의 세계란 쉽게 보고 시작했다간 코가 다섯번은 부서지는 것 같다 허허허
지난주에 비해 나의 이해상태는.. 더 낮아진 것만 같다.
이번주는 정말 휘리릭 진행되었는데!! 이제 나에게 남은 방법은 이해가 아니라 복붙. 암기뿐!
파이썬을 이용한 크롤링부터 데이터가공, 시각화까지 매우 바쁘게 진도가 나갔다.
일단 끄적였던 개념들부터 기록해보자
4주차 진행학습
* 크롤링
* 데이터가공
* 데이터시각화
셀레늄을 이용한 웹 크롤링
셀레늄은 웹 브라우저를 제어하여 웹 페이지를 자동으로 조작하고 데이터를 수집할 수 있는 기능을 제공
복잡한 웹 페이지 구조나 동적으로 로딩되는 데이터도 쉽게 크롤링할 수 있음

*다량의 데이터 수집
컨테이너 요소를 찾아 elements로 수집 & for 반복문 활용

★pandas설치하기
쉽고 직관적으로 작업할 수 있도록 설계되었고, 빠르고 유연한 데이터 구조를 제공하는 Python 패키지
*주요 기능
- 데이터의 빠른 정렬, 슬라이싱, 인덱싱
- 데이터 그룹핑, 피봇팅
- 데이터 간의 join
- 데이터 요약, 통계
- 파이썬 자료구조(리스트, 튜플, 딕셔너리 등)과의 호환
- 외부 데이터(csv, 엑셀, SQL DB, txt 등)를 다루기 용이
*설치하기
!pip install pandas
*크롤링한 자료 엑셀로 저장하기

▼ 하기와 같은 파일로 저장됨
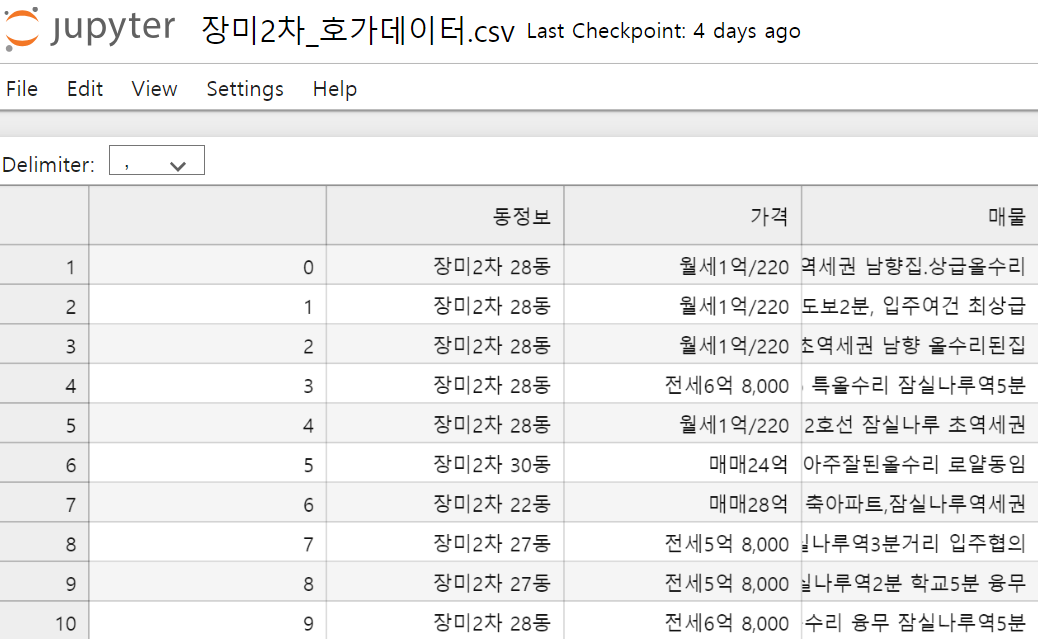
**실습예제) 구글 뉴스에 '데이터분석'을 검색 후 30페이지 내용까지 크롤링 하고 싶을 때
1) 셀레늄 시작
2) 크롬브라우저 시작
3) 구글 뉴스 '데이터분석' 검색 url 로 진입

4) 한 페이지 수집 정의 후, 원하는 범위까지 for 반복문 실행 (wow 어메이징..)

*browser.find_element(By.ID,'pnnext').click() 에서 pnnext는 "다음" 버튼 요소의 ID값
데이터분석 (numpy, pandas)
*Numpy
*Numpy 특징
- Numarray와 Numeric이라는 기존 파이썬 패키지를 계승해서 나온 수학 및 과학 연산을 위한 파이썬 패키지
- 선형대수, 행렬 또는 다차원 배열을 쉽게 처리할 수 있도록 도와주는 패키지
- 수학적인 연산처리에도 자주 활용
- 다차원 배열 객체(ndarray)를 통해 벡터 및 행렬을 사용하는 선형 대수 계산에 주로 사용
- 순수 파이썬에 비해 속도가 빠름
*pandas
*Pandas 특징
- panda는 panel data analysis 줄여서 표현
- 데이터 조작 및 분석을 위한 파이썬 패키지
- 테이블 형태의 데이터를 다루는 DataFrame(=Excel, CSV) 자료형을 제공
- SQL과 같은 데이터 생성, 조회, 수정, 삭제 등의 작업이 가능
- Numpy 기반에서 개발
- 대용량의 데이터를 다룰 때 엑셀보다 속도가 훨씬 빠름
pandas 함수
* 불러오기, 저장하기
[cvs파일]
불러오기 : 데이터변수 = pd.read_csv(파일경로)
저장하기 : 데이터변수.to_csv(파일경로)
[엑셀파일]
불러오기 : 데이터변수 = pd.read_excel(파일경로, sheet_name=시트이름)
저장하기 : 데이터변수.to_excel(파일경로, sheet_name=시트이름)
* 데이터 확인
df.shape, df.info, df.columns, df.dtypes, df.head, df.tail
* 값 정렬
sort_values
* 특정 column / row 삭제
df.drop([’column_name’], axis=1)
df.drop[’row’]
* 특정 column 이름 변경
df.rename(columns={’A’:’B’})
* DataFrame 2개 합치기
pd.concat([df1, df2])
* 중복 관리
중복확인: df.duplicated
중복제거: df.drop_duplicates
★하기 이미지로 쉽게 이해해보기
data값을 아래와 같이 설정해서 데이터프레임으로 불러오고

1. 원하는 컬럼 추출하기
(1). df.컬럼명, df['컬럼'] (컬럼을 두 개 이상 추출하고 싶다면 대괄호를 한 번 더 쓰기)

(2). df.loc[인덱스값,컬럼명]

2. 새로운 컬럼 추가하기

3. 데이터 삭제하기

4. 데이터 수정하기
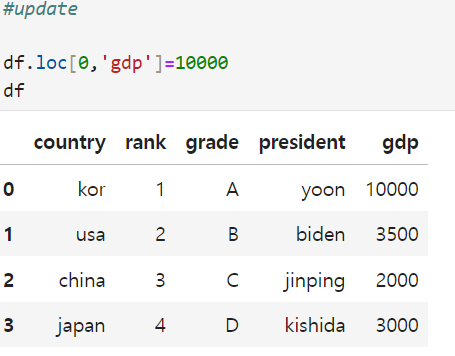
5. 함수
#집합함수
df.sum()
df.mean(numeric_only=True)
df.max()
df.min()
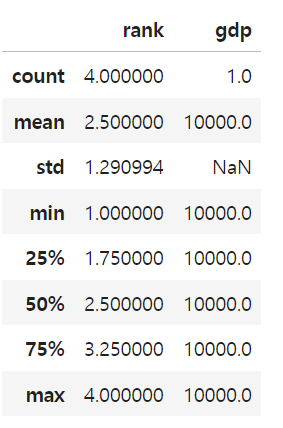
df.describe() #기술통계 데이터를 한방에 볼 수 있게됨
df.info() #정보 알 수 있음 (type,null값 등)

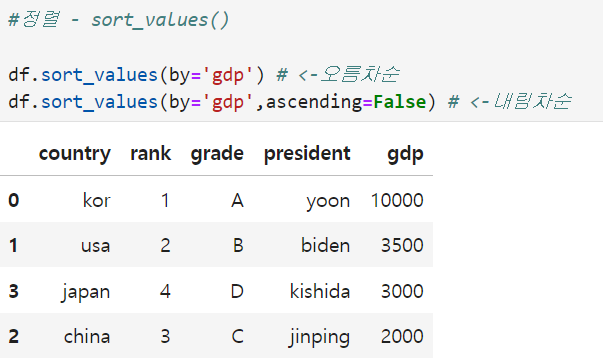
#정렬함수
sort_values()
# 결측값 처리
- (1) 삭제 - dropna() : null 데이터를 제거
- (2) 채움 - fillna() : null 데이터를 채움
**실습예제)

데이터시각화 (matplotlib,seaborn,plotly)
* matplotlib






'패스트캠퍼스🥕' 카테고리의 다른 글
| ■패스트캠퍼스 데이터 분석 부트캠프■ 8주차 #SQL 기초문법 (0) | 2024.10.11 |
|---|---|
| ■패스트캠퍼스 데이터 분석 부트캠프■ 5주차 #python 라이브러리 (6) | 2024.09.20 |
| ■패스트캠퍼스 데이터 분석 부트캠프■ 3주차 #데이터 분석을 위한 python (2) | 2024.09.06 |
| ■패스트캠퍼스 데이터 분석 부트캠프■ 2주차 #데이터 분석을 위한 기초 수학/통계 (0) | 2024.08.30 |
| ■패스트캠퍼스 데이터 분석 부트캠프■ 1주차 #엑셀을 활용한 데이터 분석 (0) | 2024.08.23 |